4. Traditional python approaches to multi cpu and nodes
Overview
Teaching: 25 min
Exercises: 5 minQuestions
How to utilise multiple cpus and nodes on Artemis
Objectives
Discover python multiprocessing and mpi execution
Python Multiprocessing
The PBS resource request #PBS -l select=1:ncpus=1 signals to the scheduler how many nodes and cpus you want your job to run with. But from within Python you may need more flexible ways to manage resources. This is traditionally done with the multiprocessing library.
With multiprocessing, Python creates new processes. A process here can be thought of as almost a completely different program, though technically they are usually defined as a collection of resources where the resources include memory, file handles and things like that.
One way to think about it is that each process runs in its own Python interpreter, and multiprocessing farms out parts of your program to run on each process.
Some terminology - Processes, threads and shared memory
A process is a collection of resources including program files and memory, that operates as an independent entity. Since each process has a seperate memory space, it can operate independently from other processes. It cannot easily access shared data in other processes.
A thread is the unit of execution within a process. A process can have anywhere from just one thread to many threads. Threads are considered lightweight because they use far less resources than processes. Threads also share the same memory space so are not independent.
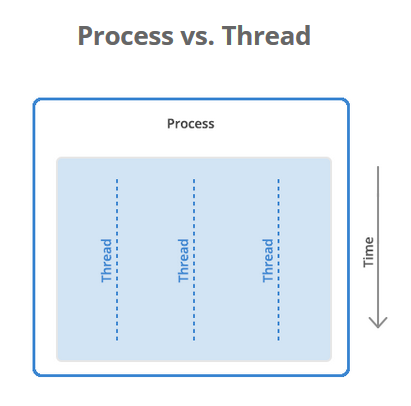
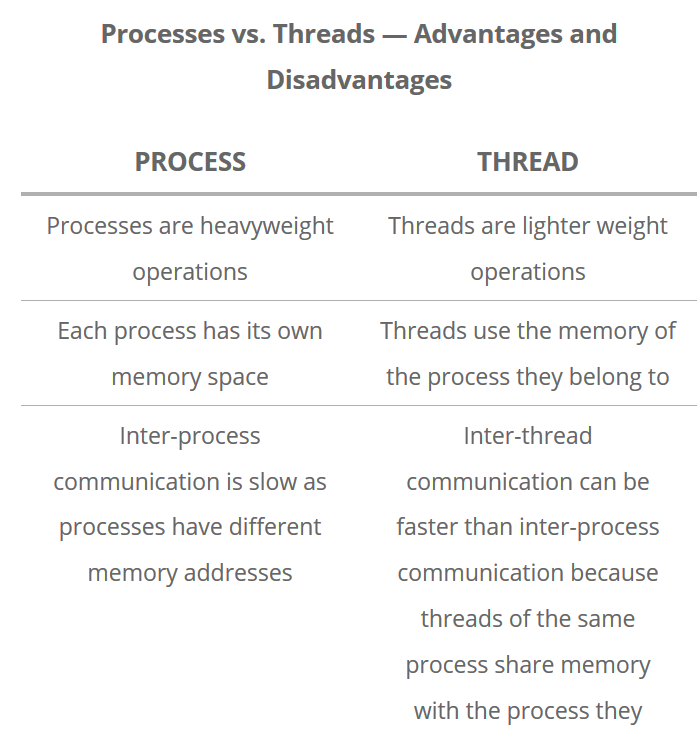
Back to python, the multiprocessing library was designed to break down the Global Interpreter Lock (GIL) that limits one thread to control the Python interpreter.
In Python, the things that are occurring simultaneously are called by different names (thread, task, process). While they all fall under the definition of concurrency (multiple things happening anaologous to different trains of thought), only multiprocessing actually runs these trains of thought at literally the same time. We will only cover multiprocessing here which assists in CPU bound operations - but keep in mind other methods exist (threading), whose implementation tends to be more low level.
Small demonstration of python multiprocessing library
Some basic concepts in the multiprocessing library are:
- the
Pool(processes)object creates a pool of processes.processesis the number of worker processes to use (i.e Python interpreters). IfprocessesisNonethen the number returned byos.cpu_count()is used. - The
map(function,list)attribute of this object uses the pool to map a defined function to a list/iterator object
To implement multiprocessing in its basic form.
Create a small python file called basic.py with the below code.
from multiprocessing import Pool
def addit(x):
return x + 1
def main():
print(addit(4))
with Pool(2) as p:
print(p.map(addit,[1,2,3]))
main()
Now, you run this either with jupyter notebook or your preferred code editor. Keep in mind Python 3 module is used (if you are trying on the HPC)
python basic.py
The output should be:
5
[2, 3, 4]
Getting Data and Files for this Course:
From here on we will either run python files locally using our conda environment that was installed in the setup, or run pbs scripts on the HPC. In both cases, the data needed is stored on the HPC in the /project/Training/AdvPyTraining folder.
Setp 1 - get data from the HPC to our local directory using the credentials you were given for todays training. Aim to be in the same folder we had run previous code locally.
scp -r ict_hpctrain<N>@hpc.sydney.edu.au:/project/Training/AdvPyTrain/ .
Step 2 - On the hpc create a new folder within the /project/Training directory, in which you will copy data to and in the near future run pbs scripts from.
mkdir /project/Training/myname
cd /project/Training/myname
rsync -av /project/Training/AdvPyTrain/files/* ./files
rsync -av /project/Training/AdvPyTrain/data/* ./data
Calculation of pi - submitting two scripts to compare multiprocessing advantage
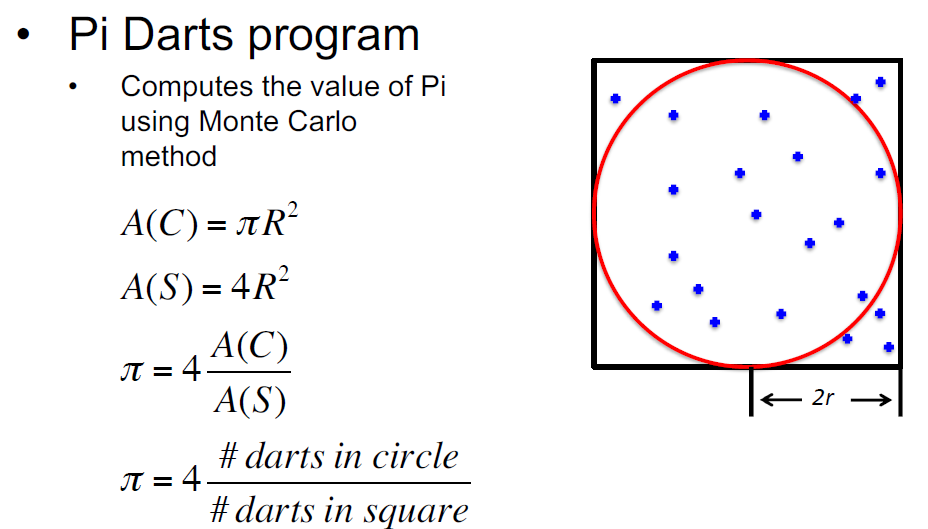
Navigate to the computepi_multiprocs.py file located in the files directory. Notice how the Pool object and map function sets off simulating an estimate of pi given a sequence of trails - the larger the trail number the closer the estimate is to pi.
Run two scripts by sumitting the run_pi.pbs file to the scheduler. This pbs script should submit two jobs that approximate pi in the same way, except one using the multiprocessing library and is slightly faster even though the same Artemis resources are requested.
cd files
qsub run_pi.pbs
While it is running, have a look at the code.
When it is completed, check out the output of the two methods in out_pi.o?????. Which method was faster? Did you get the kind of speed-up you were expecting?
MPI: Message Passing Interface
MPI is a standardized and portable message-passing system designed to function on a wide variety of parallel computers. The standard defines the syntax and semantics of a core of library routines useful to a wide range of users writing portable message-passing programs in C, C++, and Fortran. There are several well-tested and efficient implementations of MPI, many of which are open-source or in the public domain.
MPI for Python, found in mpi4py, provides bindings of the MPI standard for the Python programming language, allowing any Python program to exploit multiple processors. This simple code demonstrates the collection of resources and how code is run on different processes:
#Run with:
#mpiexec -np 4 python mpi.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
print("I am rank %d in group of %d processes." % (rank, size))
If you want to submit this python script on Artemis, the PBS script is below. Notice here we are requesting 4 seperate nodes in the PBS script. This amount aligns with the -np 4 flag (number of processes), so each process is seperate and executed on different nodes on Artemis.
#!/bin/bash
#PBS -P Training
#PBS -N testmpi
#PBS -l select=4:ncpus=1:mem=1GB
#PBS -l walltime=00:10:00
#PBS -q defaultQ
cd $PBS_O_WORKDIR
module load python
module load openmpi-gcc
mpiexec -np 4 python mpi.py > mpi.out
Keep in Mind
There is generally a sweet spot in how many processes you create to optimise the run time. A large number of python processes is generally not advisable, as it involves a large fixed cost in setting up many python interpreters and its supporting infrastructure. Play around with different numbers of processes in the pool(processes) statement to see how the runtime varies.
Useful links
https://realpython.com/python-concurrency/
https://docs.python.org/3/library/multiprocessing.html
https://www.backblaze.com/blog/whats-the-diff-programs-processes-and-threads/
https://pawseysc.github.io/training.html
Notes
1↩As you should recall from the Introduction to Artemis HPC course, the scheduler is the software that runs the cluster, allocating jobs to physical compute resources. Artemis HPC provides us with a separate ‘mini-cluster’ for Training, which has a separate PBS scheduler instance and dedicated resources.
Key Points
load multiprocessing library to execute a function in a parallel manner