6. Introducing dask Bag and more dask examples
Overview
Teaching: 20 min
Exercises: 20 minQuestions
How do I deal with large irregular data and show me some real world examples of Dask
Objectives
Deal with semi-structured and unstructured data in memory efficient and parallel manner
Show me examples of using Dask on Large Datasets
What is Dask Bag
Dask Bag implements operations like map, filter, groupby and aggregations on collections of Python objects. It does this in parallel and in small memory using Python iterators.
Dask Bags are often used to do simple preprocessing on log files, JSON records, or other user defined Python objects
Execution on bags provide two benefits:
- Parallel: data is split up, allowing multiple cores or machines to execute in parallel
- Iterating: data processes lazily, allowing smooth execution of larger-than-memory data, even on a single machine within a single partition
By default, dask.bag uses dask.multiprocessing for computation. As a benefit, Dask bypasses the GIL and uses multiple cores on pure Python objects. As a drawback, Dask Bag doesn’t perform well on computations that include a great deal of inter-worker communication.
Because the multiprocessing scheduler requires moving functions between multiple processes, we encourage that Dask Bag users also install the cloudpickle library to enable the transfer of more complex functions
What are the drawbacks ?
-
Bag operations tend to be slower than array/DataFrame computations in the same way that standard Python containers tend to be slower than NumPy arrays and Pandas DataFrames
-
Bags are immutable and so you can not change individual elements
-
By default, bag relies on the multiprocessing scheduler, which has known limitations - the main ones being: a, The multiprocessing scheduler must serialize data between workers and the central process, which can be expensive b, The multiprocessing scheduler must serialize functions between workers, which can fail. The Dask site recommends using cloudpickle to enable the transfer of more complex functions.
To learn Bag - Lets get our hands dirty with some examples
Dask API: Dask Bag API
Using the data in our /files directory, lets create a dask bag from the contents of the json files. The contents are organised in a semi-structured way, hence converting this directly into a dataframe requires some extra steps.
Before we start, some python packages are needed. Types these commands directly into ipython
import dask.bag as db
import json
dask_bag = db.read_text('./data/*.json').map(json.loads)
Most common functions are :
-
map: Apply a function elementwise across one or more bags.
-
filter: Filter elements in collection by a predicate function.
-
take : Take the first k elements.(the Head equivalent of a dask dataframe
For instance:
dask_bag.take(1)
{'age': 50,
'name': ['Ulysses', 'Rice'],
'occupation': 'Technical Director',
'telephone': '+1-(147)-837-3639',
'address': {'address': '1103 Wright Street', 'city': 'West Linn'},
'credit-card': {'number': '3787 382163 49562', 'expiration-date': '12/21'}},)
Dask Bag Exercise 1 :
Of the people who are less than 40yrs old, find the top 5 most common cities they reside in. Use functions:
- filter : filter records
- lambda expressions
- map : map a function
- frequencies : count number of occurences of each distinct category
- topk : K largest elements in a collection
Dask Bag Exercise 2 :
Using the dask_bag data, extract age, occupation and city for each person and place inside a nice dask dataframe. Hint, create a function that extracts relevant fields and returns a dict.
OPTIONAL PANGEO GEOSCIENCE EXAMPLE - MULTI DIMENSIONAL DATA
Pangeo is a community promoting open, reproducible, and scalable science.
In practice it is not realy a python package, but a collection of packages, supported datasets, tutorials and documentation used to promote scalable science. Its motivation was driven by data becoming increasingly large, the fragmentation of software making reproducability difficult, and a growing technology gap between industry and traditional science.
As such the Pangeo community supports using dask on HPC. We will run through an example of using our new found knowledge of dask on large dataset computation and visualisation.Specifically this pangeo example is a good illustration of dealing with an IO bound task.
The example we will submit is an altered version of Pangeos meteorology use case found here: https://pangeo.io/use_cases/meteorology/newmann_ensemble_meteorology.html
Rather than using a dask dataframe, data is loaded from multiple netcdf files in the data folder relative to where the script resides. Xarray is an opensource python package that uses dask in its inner workings. Its design to make working with multi-dimensional data easier by introducing labels in the form of dimensions, coordinates and attributes on top of raw NumPy-like arrays, which allows for a more intuitive, more concise, and less error-prone developer experience.
It is particulary suited for working with netcdf files and is tightly integrated with dask parallel computing.
And have a look at the data
import xarray as xr
data = xr.open_dataset('../data/conus_daily_eighth_2008_ens_mean.nc4')
data
You should see the following metadata that holds 3 dimenstional information (latitude, longditude and time) on temperature and precipitation measurements.
In [42]: data
Out[42]:
<xarray.Dataset>
Dimensions: (lat: 224, lon: 464, time: 366)
Coordinates:
* time (time) datetime64[ns] 2008-01-01 2008-01-02 ... 2008-12-31
* lat (lat) float64 25.12 25.25 25.38 25.5 ... 52.62 52.75 52.88 53.0
* lon (lon) float64 -124.9 -124.8 -124.6 -124.5 ... -67.25 -67.12 -67.0
Data variables:
elevation (lat, lon) float64 ...
pcp (time, lat, lon) float32 ...
t_mean (time, lat, lon) float32 ...
t_range (time, lat, lon) float32 ...
Attributes:
history: Wed Oct 24 13:59:29 2018: ncks -4 -L 1 conus_daily_eighth_2...
NCO: netCDF Operators version 4.7.4 (http://nco.sf.net)
institution: National Center fo Atmospheric Research (NCAR), Boulder, CO...
title: CONUS daily 12-km gridded ensemble precipitation and temper...
Find out how large is the file.
print('memory gb',format(data.nbytes / 1e9))
What is the average elevation over lat and long dimensions.
data.elevation.mean()
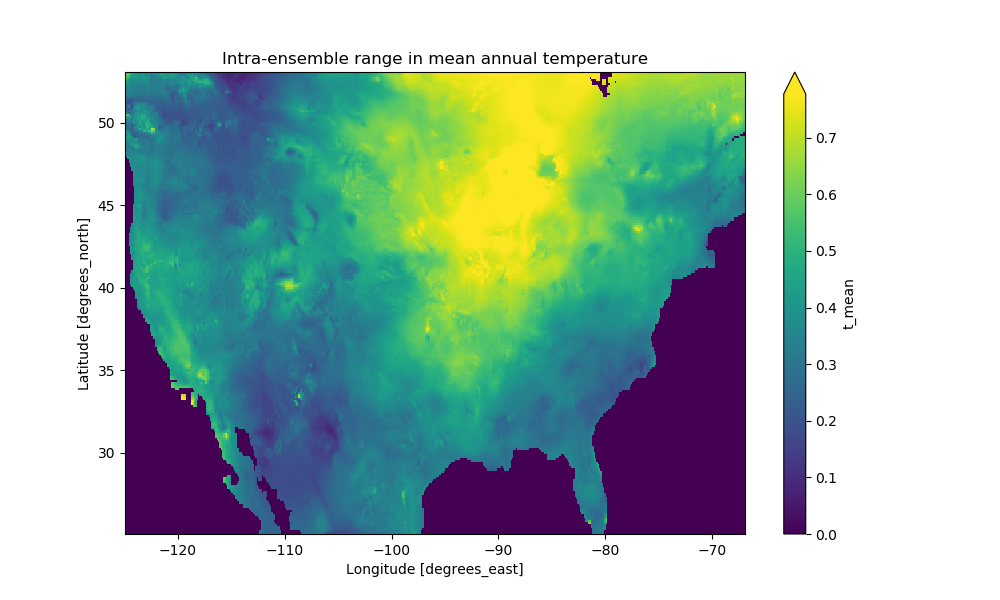
On the HPC, run the PBS script that creates an image of latitude and longitudinal data.
Submit the pangeo.pbs file to the scheduler located in the /
qsub pangeo.pbs
Png files should be created based on calculation in the code that measure the variance in temperatures (max minus min observations). As seen before, these calculations are triggered by a .compute() call. Two images are created, with one demostrating how we can persist the xarray dataset in memory for quick retrievals via the .persist() call.
Lets see the image. If you have X11 forwarding enabled you can view it directly from artemis. Alternatively, use scp to copy it locally and view.
module load imagemagick
display variance_temp.png &
Some links:
on dask bag fundamentals https://docs.dask.org/en/latest/bag.html
Bag API’s: https://docs.dask.org/en/latest/bag-api.html
Dask bag limitations: https://docs.dask.org/en/latest/shared.html
Pangeo info: https://pangeo.io/#what-is-pangeo
Xarray: http://xarray.pydata.org/en/stable/
Xarray API: http://xarray.pydata.org/en/stable/generated/xarray.open_dataset.html
Key Points
Dask Bag uses map filter and group by operations on python objects or semi/unstrucutred data
dask.multiprocessing is under the hood
Xarray for holding scientific data