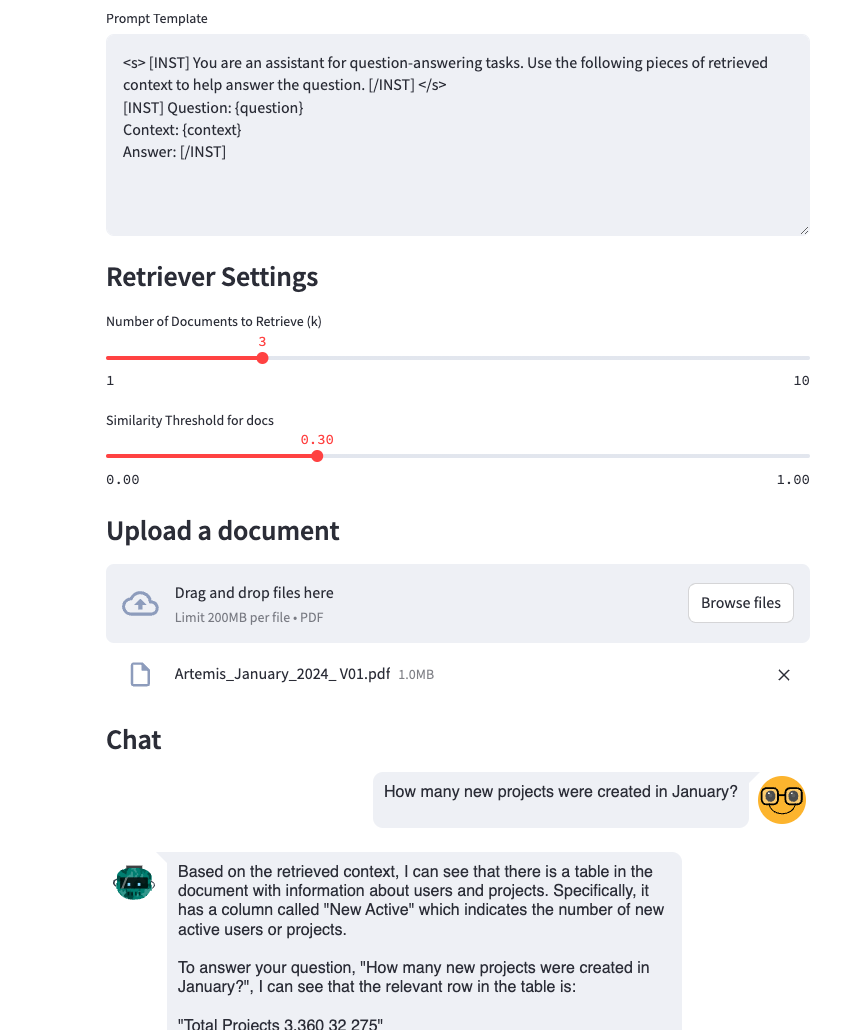
Don't want to share your private data? You can run your own local LLM to query your own documents in a couple steps with a RAG!
- Get a local LLM
- Get Ollama
- Follow the instructions to install.
- Open a Terminal and download a model (e.g. llama3.1).
- And serve the model locally.
ollama pull llama3.1
ollama serve
- Get the interface: We will use LangChain to handle the vector store and Steamlit to give you a fancy front-end to interact with the LLM and data upload.
git clone https://github.com/Sydney-Informatics-Hub/LLM-local-RAG/
cd LLM-local-RAG
conda create -n localrag python=3.11 pip
conda activate localrag
pip install langchain streamlit streamlit_chat chromadb fastembed pypdf langchain_community
- Start chatting!
streamlit run app.py
Upload your docs and start asking questions!