Python
Github repository: https://github.com/Sydney-Informatics-Hub/geodata-harvester
Pipeline Overview
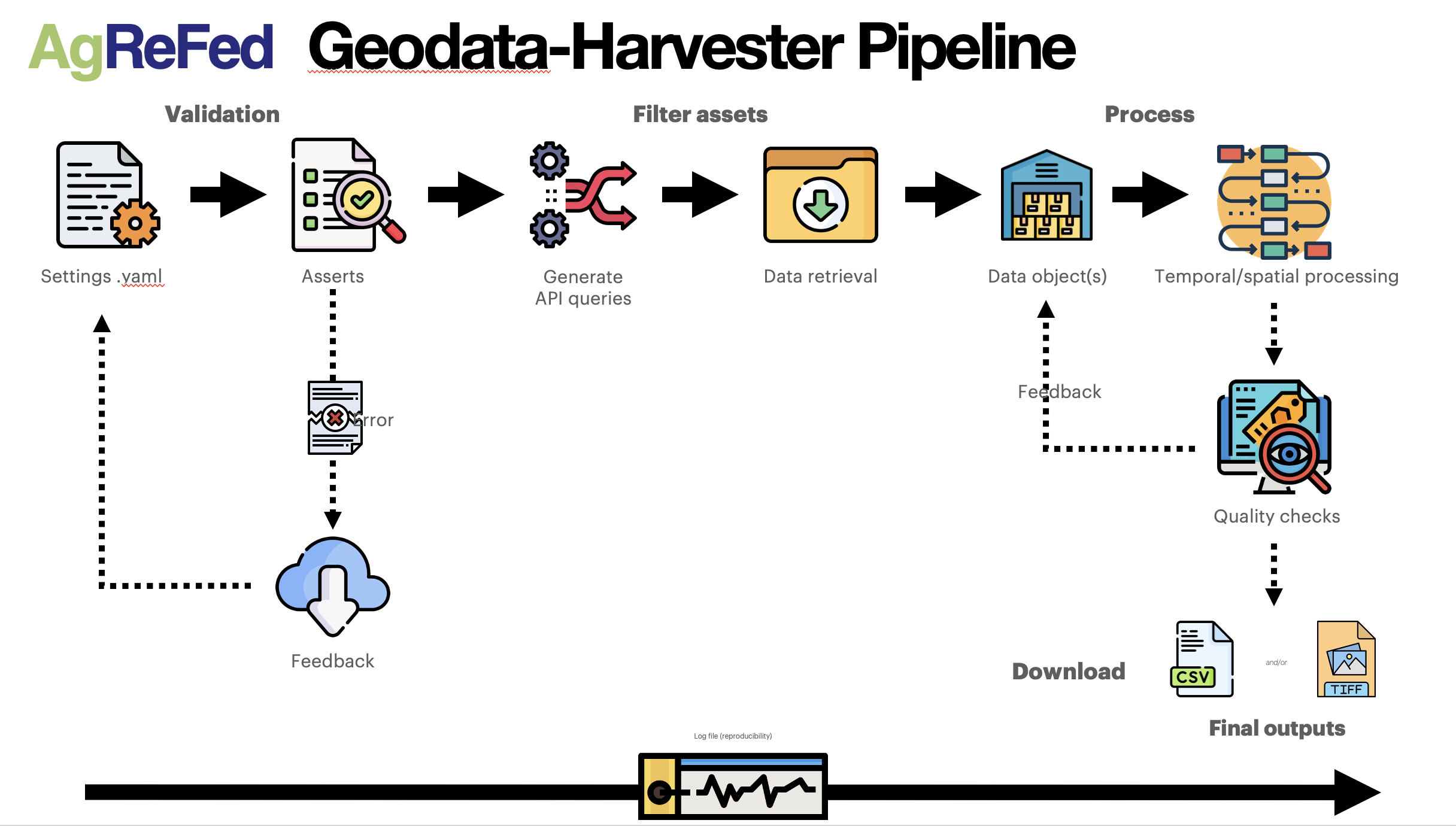
Functionality
The main goal of the Data Harvester is to enable researchers with reusable workflows for automatic data extraction and processing:
- Retrieve: given set of locations, automatically access and download multiple data sources (APIs) from a diverse range of geospatial and soil data sources
- Process: Spatial and temporal processing, conversion to dataframes and custom raster-files
- Output: Ready-made dataset for machine learning (training set and prediction mapping)
Geodata-Harvester is designed as a modular and maintainable project in the form of a multi-stage pipeline by providing explicit boundaries among tasks. To encourage interaction and experimentation with the pipeline, multiple frontend notebooks and use case scenarios are provided.
Installation
Geodata-Harvester can be run on cloud-servers (e.g., in JupyterHub environment) or on your local machine. Example notebooks for importing and using the package can be found in the folder notebooks. To install the package run one of the following:
Conda or Mamba
The package geodata-harvester is available via the conda-forge channel:
conda install geodata-harvester -c conda-forgeNote that the geodata-harvester is imported with underscore as
import geodata_harvesterPip
Installation via pypi requires a pre-installation of gdal (see, e.g., pypi.org/project/GDAL/installation guide) in your environment. Once gdal is installed, you can install geodata-harvester via
pip install geodata-harvesterThe geodata-harvester library can then be imported via
import geodata_harvesterRequirements
If you like to develop Data Harvester locally, it is recommended to setup a virtual environment for the installation, e.g., via conda miniforge (see for dependencies environment.yaml).
To build the Geodata Harvester from scratch see the dependencies listed in the environment file.
To install the dependencies for the Geodata Harvester you may use the environment file directly in conda:
wget https://raw.githubusercontent.com/Sydney-Informatics-Hub/geodata-harvester/main/environment.yaml
conda env create -f environment.yaml -n gdh
conda activate gdhUsage
You may now invoke the geodata-harvester directly from a python terminal with:
import geodata_harvester as gh
gh.harvest.run()Note the subtle but important difference in use of an underscore _ to import the package and the use of a dash - to install it!
To get started, some example workflows are provided as Jupyter notebooks:
Options and user settings are defined by the user in the settings; see for settings documentation Settings_Overview
Run the jupyter notebooks in the folder notebooks.
API reference
A detailed API documentation is available here.
New data source modules
The Geodata-Harvester is designed to be extendable and new data source modules can be added as Python modules (for examples, see getdata_*.py modules). If you would like to add a new data source, please follow the adding new data source guidelines
We recommend to check the existing data source modules for inspiration. If you would like to contribute your data source module to the geodata-harvester package, please see the Contributing page
Contribution
Your contributions can help improve the software and make it more useful for others. We are happy for any contribution to the geodata-harvester, whether feedbacks and bug reports via github Issues, adding use-case examples via notebook contributions, to improving source-code and adding new or updating existing data source modules.
To contribute to the development and to understand how the Geodata Harvester works, visit the the Contributing page
Attribution and Acknowledgments
This software was developed by the Sydney Informatics Hub, a core research facility of the University of Sydney, as part of the Data Harvesting project for the Agricultural Research Federation (AgReFed).
Acknowledgments are an important way for us to demonstrate the value we bring to your research. Your research outcomes are vital for ongoing funding of the Sydney Informatics Hub.
If you make use of this software for your research project, please include the following acknowledgment:
“This research was supported by the Sydney Informatics Hub, a Core Research Facility of the University of Sydney, and the Agricultural Research Federation (AgReFed).”
AgReFed is supported by the Australian Research Data Commons (ARDC) and the Australian Government through the National Collaborative Research Infrastructure Strategy (NCRIS).
Code of Conduct
Please keep in mind that the geodata-harvester project follows the GitHub Community Code of Conduct, which requires respectful and professional behavior.
We appreciate your interest and contributions to the geodata-harvester project and look forward to working with you! If you have any questions or need help, don’t hesitate to reach out.